

11·
1 month agoYes its fantastic 👍🦾
Yes its fantastic 👍🦾
Brave browser is the solution.

They are so good at advertising Linux that they have 73% of desktop market share while linux has less than 5% according to statcounter
🤯🤯
Lol
Yes that is the point behind the ‘you wouldn’t download a car’ meme 🙂
It’s funny you mention the Katy Perry chord case, because Damien Riehl, who made the argument I referenced in my original post, actually talked about this exact case in the podcast I mentioned. He noted that Katy Perry was initially sued and a jury awarded $2.8 million over a very simple melody that appeared over 8,000 times in Riehl’s dataset of generated melodies. However, after Riehl gave his TED talk about his “All the Music” project in early 2020, the judge reversed the jury verdict, saying the melody was unoriginal and therefore uncopyrightable.
Thank you
And they've downloaded and read millions of books without paying for them.
Do you have a source on that?
OpenAI like other AI companies keep their data sources confidential. But there are services and commercial databases for books that people understand are commonly used in the AI industry.
I am thrilled to see the output you get!
Time will prove you wrong
Those claiming AI training on copyrighted works is “theft” are misunderstanding key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is more akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was found to be legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.

No this is obviously chatgpt image
On a side note the free gemini version (whichever model they use) is absolute poo poo compared to free Claude or even Chatgpt.
“Everyone that doesn’t share my specific preferences is a sheep (╯° □°) ╯”
I shall not stoop so low as to using a browser named ““floorp””.


{kind=link}
{kind=link}
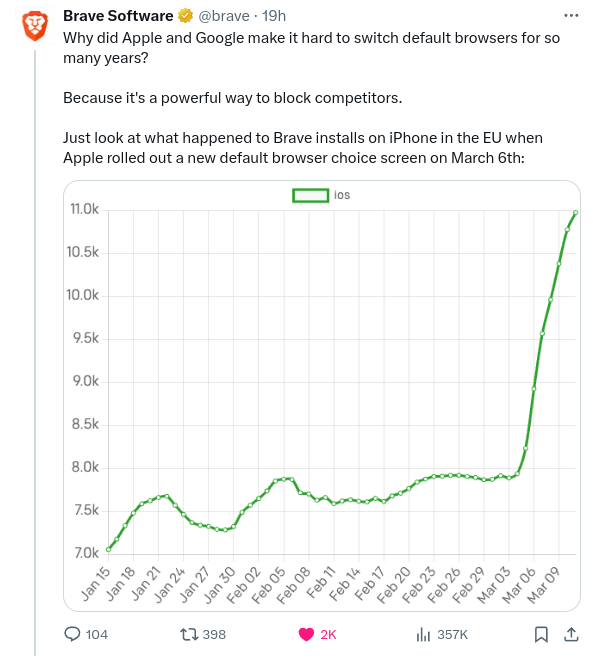{kind=link}
{kind=link}
Cringe
2020 called, they want their self-pity memes back